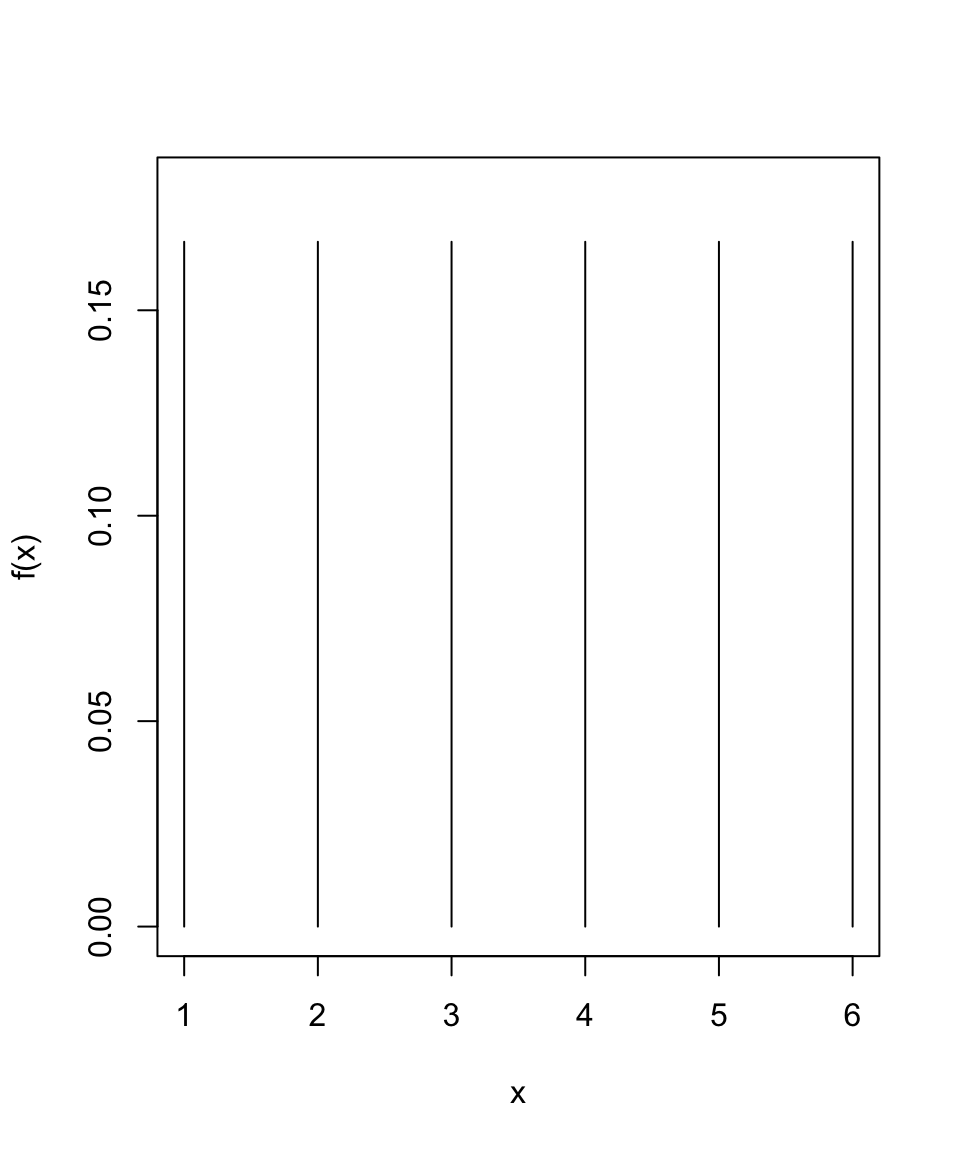
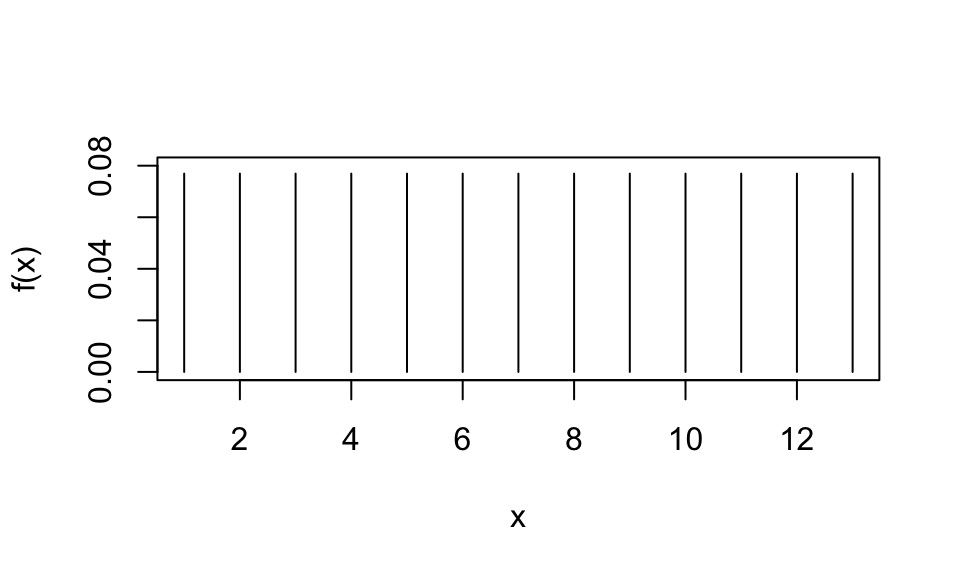
Una v.a. \(X\) tiene distribución uniforme discreta sobre el conjunto de valores \(\{1,2,...,N\}\) si la función de densidad está dada por \[f(x)=\begin{cases}
1/N &\text{si }x=1,2,...,N\\
0 &\text{si no}\\
\end{cases}\]
Principal característica: Todos los valores de \(X\) tienen la misma probabilidad.
Ejemplo 2 vendedoras
Una inmobiliaria tiene vendedores para un nuevo proyecto de casas, \(X\) y \(Y\) es el número de casas que vende en un mes Ana y Carolina, respectivamente,
“Promedio” de Carolina: \(0,15*0 + 0,3*1 + 0,3*2 + 0,25*3=1,65\)
En promedio, (a la larga, en términos generales) Carolina vende más que Ana.
Esperanza de una v.a. discreta
Corresponde al promedio de los valores de una v.a., ponderado por las probabilidades de ocurrencia.
\[\mu=E(X)=\sum x_iPr(X=x_i)\] . . .
\(E(X)\) representa el promedio de los valores de \(X\) después de repetir muchas veces el experimento.
¡Similar a cómo se computa la nota final de un ramo!
Esperanza de una v.a. discreta
Ejemplo, \(X=\) el resultado de lanzar un dado. \[E(X)=1*\frac{1}{6}+2*\frac{1}{6}+...+6*\frac{1}{6}=3.5\] . . .
Lancemos un dado muchas veces, y vemos el promedio de los resultados:
Lanzamiento
1
2
3
4
5
…
Resultado
3
5
3
1
6
…
Promediar los resultados después de 5, 10, 20 y 50 lanzamientos. Los promedios obtenidos son aproximadamente 3.5?
Varianza de una v.a. discreta
Corresponde a la varianza de los valores de una v.a., ponderado por las probabilidades de ocurrencia. \[\sigma^2=Var(X)=\sum (x_i-\mu)^2Pr(X=x_i)\]
\(Var(X)\) representa la varianza de los valores de \(X\) después de repetir muchas veces el experimento.
\[Var(X)=E(X-\mu)^2=E(X^2)-\mu^2\]
Varianza de una v.a. discreta
\(X=\) el resultado de lanzar un dado. \[Var(X)=(1-3.5)^2*\frac{1}{6}+(2-3.5)^2*\frac{1}{6}+...+(6-3.5)^2*\frac{1}{6}=2.9167\] . . .
Lancemos un dado muchas veces, y vemos el promedio de los resultados:
Lanzamiento
1
2
3
4
5
…
Resultado
3
5
3
1
6
…
Sacar varianza a los resultados después de 5, 10, 20 y 30 lanzamientos. Las varianzas obtenidas son aproximadamente 2.9167?
Distribución uniforme discreta
Una v.a. \(X\) tiene distribución uniforme discreta sobre el conjunto de valores \(\{1,2,...,N\}\) si la función de densidad está dada por \[f(x)=\begin{cases}
1/N &\text{si }x=1,2,...,N\\
0 &\text{si no}\\
\end{cases}\]
\[E(X)=\frac{N+1}{2}\]\[Var(X)=\frac{N^2-1}{12}\]
Distribución Bernoulli
Esta distribución denota el resultado de un experimento con solo dos posibles resultados, etiquetados como éxito y fracaso.
La probabilidad de resultar éxito se denota por \(p\), y la de fracaso, \(1-p\).
La v.a. \(Ber(p)\) denota el éxito con 1 y el fracaso con 0.
\[f(x)=\begin{cases}
p &\text{si }x=1\\
1-p &\text{si }x=0\\
\end{cases}\]
Interpretación de distribución Bernoulli
En una pandemia, el contagio de la enfermedad en una persona de cierto grupo etario sigue una distribución \(Ber(0.25)\).
Cada persona puede presentar dos posibles situaciones: contagiarse o no.
La probabilidad de que una persona de este grupo etario se contagie es de 0.25, ó 25%.
La probabilidad de que una persona de este grupo etario no se contagie es de 0.75, ó 75%.
Esperanza de distribución Bernoulli
Si \(X\sim Ber(p)\), entonces: \[E(X)=p\]\[Var(X)=p(1-p)\]
Distribución Binomial
Situación: repetición de un experimento Bernoulli (éxito o fracaso): \(n\) repeticiones o una serie de \(n\) experimentos Bernoulli. La distribución Binomial denota el número total de éxitos.
Ejemplo: Un asesor de un banco llama a 15 clientes para ofrecer un seguro anti fraude, la probabilidad de que en una llamada logre vender el seguro es de 17%, \(n=15\), \(p=0.17\)
Ejemplo: En un supermercado chico de 20 empleados, cada empleado tiene probabilidad de 10% de contagiarse de cierta enfermedad \(n=20\), \(p=0.1\)
Distribución Binomial
Notación: \(X\sim Binom(n,p)\), donde \(p\) es la probabilidad de éxito del ensayo Bernoulli.
Valores: \(X\) toma valores: 0, 1, …, \(n\)
Ejemplo 1 (seguros de autos).
Situación: Una empresa de seguros de autos en una semana vende 10 seguros contra todo riesgo para un mismo tipo de autos, si la probabilidad de presentar siniestro de un auto es de 15%, se quiere conocer el comportamiento de autos que presenten siniestro.
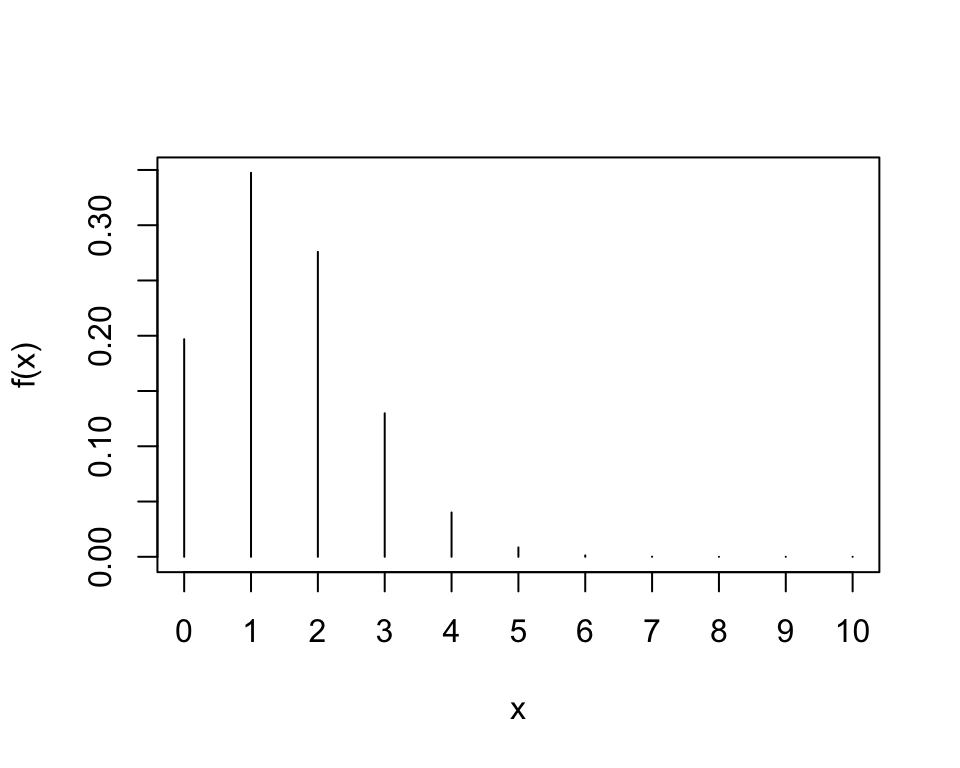
Notaciones:\(X\) denota el número de autos que presenten siniestro, posibles valores de \(X\): 0, 1, …, 10.
\(X\sim Binom(10, 0.15)\).
Ejemplo 1 (seguros de autos).
Preguntas:
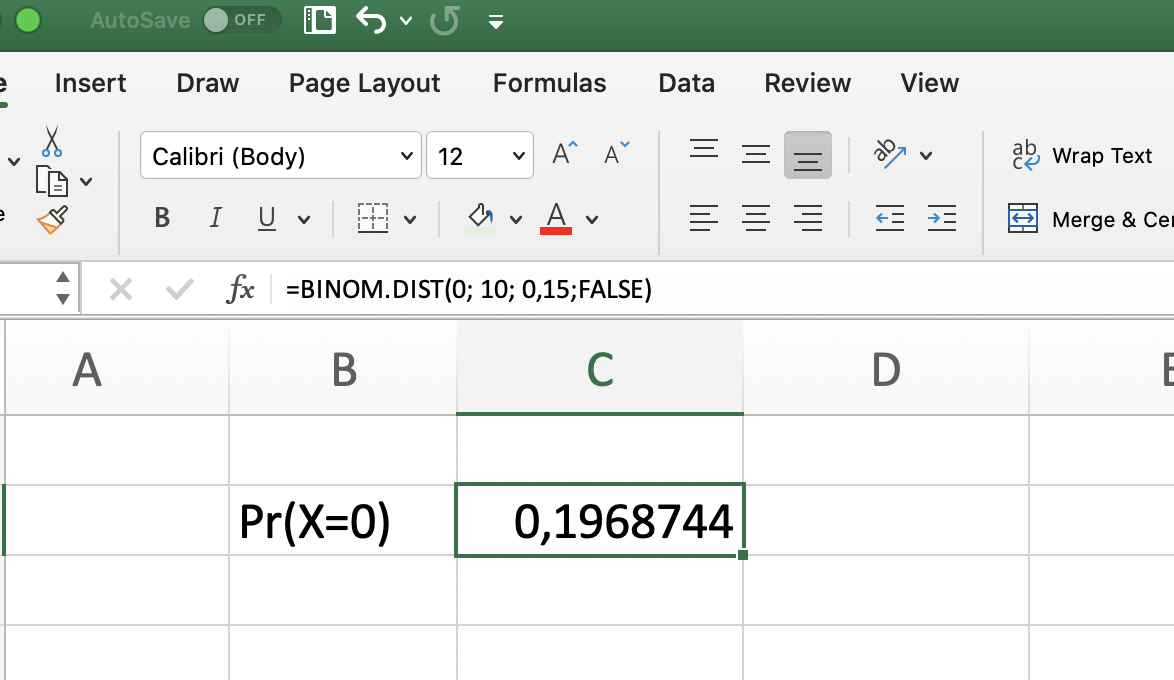
¿Qué tan probable es que ningún auto presente siniestro? \(Pr(X=0)\)
¿Qué tan probable es que 2 de los 10 autos presenten siniestro? \(Pr(X=2)\)
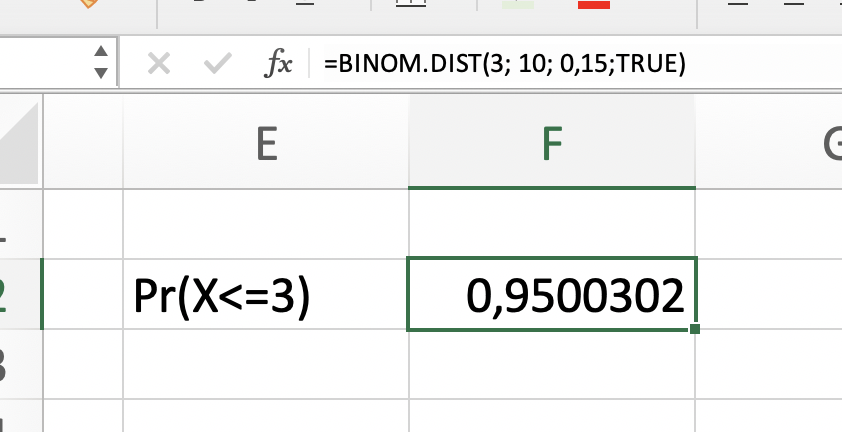
¿Qué tan probable es que a lo más 3 de los 10 autos presenten siniestro? \(Pr(X\leq3)\)
¿Qué tan probable es que más de 4 de los 10 autos presenten siniestro? \(Pr(X>4)\)
En R, usamos pbinom para las probabilidaes acumulativas
# Pr(X<=3)pbinom(3, 10, 0.15)
[1] 0.9500302
Ejemplo 1 (seguros de autos).
Probabilidad de que más de 4 de los 10 autos presenten siniestro: \(Pr(X>4) = Pr(X=5)+Pr(X=6)+...+Pr(X=10)=0.009874=0.9874\%\)
\(Pr(X>4) = 1-Pr(X\leq4)=0.009874=0.9874\%\)
Distribución Binomial
En Excel, usar la función BINOM.DIST
Ejemplo 1 (seguros de autos).
En R
# Pr(X>4)1-pbinom(4, 10, 0.15)
[1] 0.009874091
Propiedades de distribución Binomial
Si \(X\sim Binom(n,p)\), entonces \[E(X)=np\]\[Var(X)=np(1-p)\]
En el ejemplo de seguros de autos, \(E(X)=10*0.15=1.5\) autos, coincide lo observado en la gráfica de \(f(x)\): los valores más probables son: 0, 1, 2, y 3.
Distribución Poisson
Situación: La distribución Poisson es comúnmente utilizado para describir el número de sucesos en un determinado intervalo de tiempo y/o espacio geográfico.
Número de accidentes diarios de autos en una ciudad
Número de personas que llegan a la urgencia de un hospital en un día.
Distribución Poisson
Notación\(X\sim Poisson(\lambda)\) (\(\lambda\) se lee lambda): \(X\) tiene distribución Poisson con parámetro \(\lambda\).
Valores de\(X\): \(X\) toma valores 0, 1, 2, … . No tiene un límite superior.
\(X\) es una variable aleatoria discreta.
Función de densidad Poisson
Si \(X\sim Poisson(\lambda)\), entonces \[f(x)=\begin{cases}
\dfrac{e^{-\lambda}\lambda^x}{x!} &\text{si }x=0,1,2,...,\\
0 &\text{si no}\\
\end{cases}\]
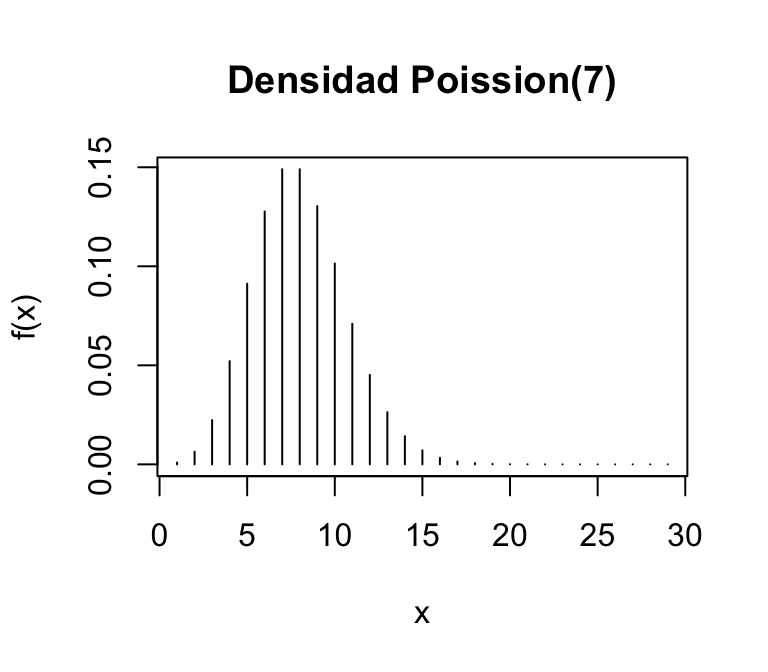
Distribución Poisson
Distribución Poisson
Distribución Poisson
De las gráficas anteriores, se observan que:
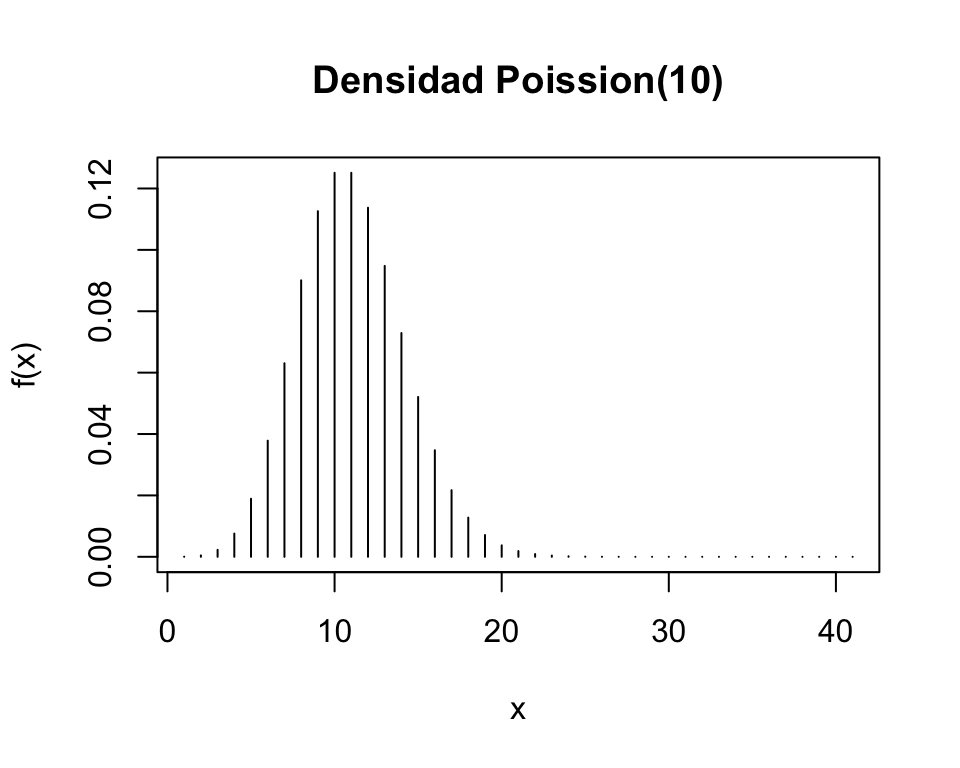
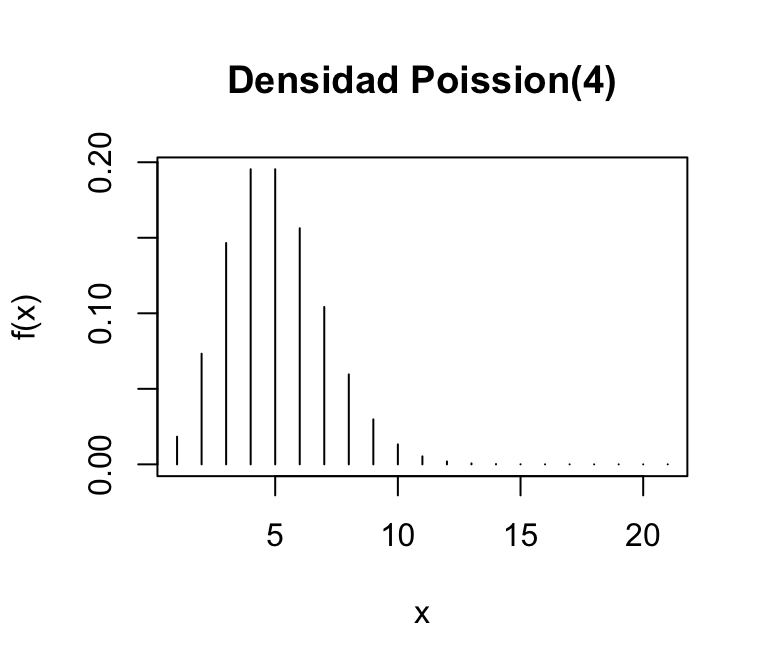
En la densidad de \(Poisson(4)\), los valores más probabiles de \(X\) están alrededor de 4.
En la densidad de \(Poisson(7)\), los valores más probabiles de \(X\) están alrededor de 7.
Se puede concluir que:
El parámetro \(\lambda\) indica dónde están los valores más probables de la variable \(X\)
\(E(X)=\lambda\)
Ejemplo número de peticiones
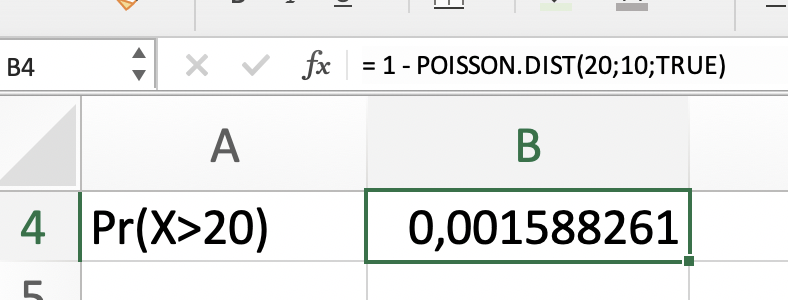
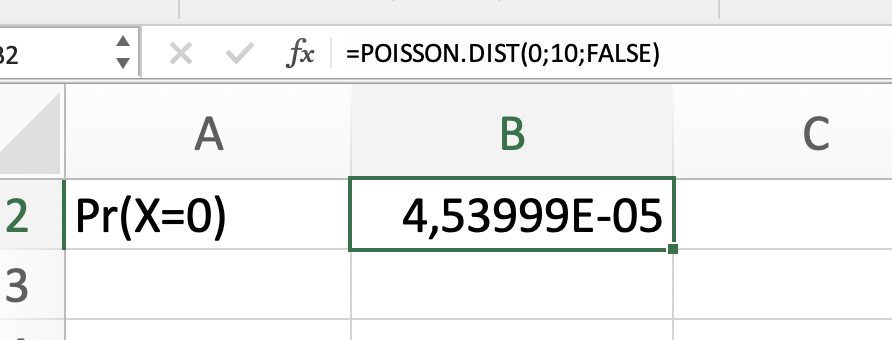
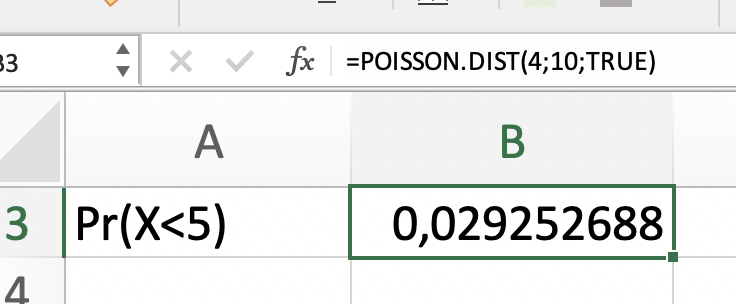
El número de peticiones que llegan diariamente a una oficina de ministerio público sigue una distribución Poisson con parámetro 10, calcular probabilidad de que:
en un día determinado no llegue ninguna petición.
en un día determinado llegue exactamente 4 petición.
en un día determinado llegue menos de 5 peticiones.
en un día determinado llegue más de 20 peticiones.
en un día determinado llegue entre 5 y 14 peticiones.


 . . .
. . .