pais ingreso pc
1 Alemania 27610.0 48.47
2 Arabia Saudita 13230.0 13.67
3 Argentina 11410.0 8.20
4 Australia 28780.0 60.18
5 Bélgica 28920.0 31.81
6 Brasil 7510.0 7.48
7 Bulgaria 75.4 5.19
8 Canadá 30040.0 48.70
9 China 4980.0 2.76
10 Colombia 6410.0 4.93
11 Ecuador 3940.0 3.24
12 Egipto 3940.0 2.91
13 España 22150.0 19.60
14 Estados Unidos 37750.0 40.57
15 Francia 27640.0 34.71
16 Grecia 19900.0 8.17
17 Guatemala 4090.0 1.44
18 Hungría 13840.0 10.84
19 India 2880.0 0.72
20 Indonesia 3210.0 1.19
21 Italia 26830.0 23.07
22 Japón 28450.0 38.22
23 México 8980.0 8.30
24 PaísBajos 28560.0 46.66
25 Pakistán 2040.0 0.42
26 Polonia 11210.0 14.20
27 ReinoUnido 27690.0 40.57
28 RepúblCheca 15600.0 17.74
29 Rusia 8950.0 8.87
30 Sudáfrica 10130.0 7.26
31 Suecia 26710.0 62.13
32 Suiza 32220.0 70.87
33 Tailandia 7450.0 3.98
34 Venezuela 4750.0 6.09Modelo de regresión lineal simple
Hanwen Zhang, Ph.D.
2022-II
Datos sobre el número de computadoras personales (PC) por cada 100 personas, y el ingreso per cápita ajustado por el poder adquisitivo en dólares
Una muestra de 34 países.
Corresponden a 2003 y se obtuvieron del Statistical Abstract of the United States, 2006.
Presentación del modelo de regresión lineal simple
- Variable dependiente \(Y\)
- Variable independiente \(X\)
- \(n\) unidades de observaciones (personas, hogares, empresas, paises, etc)
| Individuo | \(Y\) | \(X\) |
|---|---|---|
| 1 | \(y_1\) | \(x_1\) |
| 2 | \(y_2\) | \(x_2\) |
| i | \(y_i\) | \(x_i\) |
| n | \(y_n\) | \(x_n\) |
Modelo de regresión lineal simple
\[y_i=\underbrace{\beta_0+\beta_1x_i}_{determinístico}+\underbrace{u_i}_{aleatorio}\ \ \ \ \text{para todo $i=1,\cdots,n$}\]
\[ \begin{cases} y_1=\beta_0+\beta_1x_1+u_1 \\ y_2=\beta_0+\beta_1x_2+u_2 \\ \hspace{1cm}\vdots\\ y_n=\beta_0+\beta_1x_n+u_n \\ \end{cases} \]
Modelo de regresión lineal simple
Modelo de regresión lineal simple
Importancia del término (error) aleatorio \(u_i\)
- Falencia de la teoría económica
- Falta de variables explicativas
- Aleatoriedad en las unidades de observaciones
- Modelo determinístico incorrecto
En el término \(u_i\) está cualquier componente/característica no incluido en el modelo
Conocer el comportamiento de \(u_i\) permite evaluar qué tan bien el modelo se ajusta a los datos
Estimación del modelo
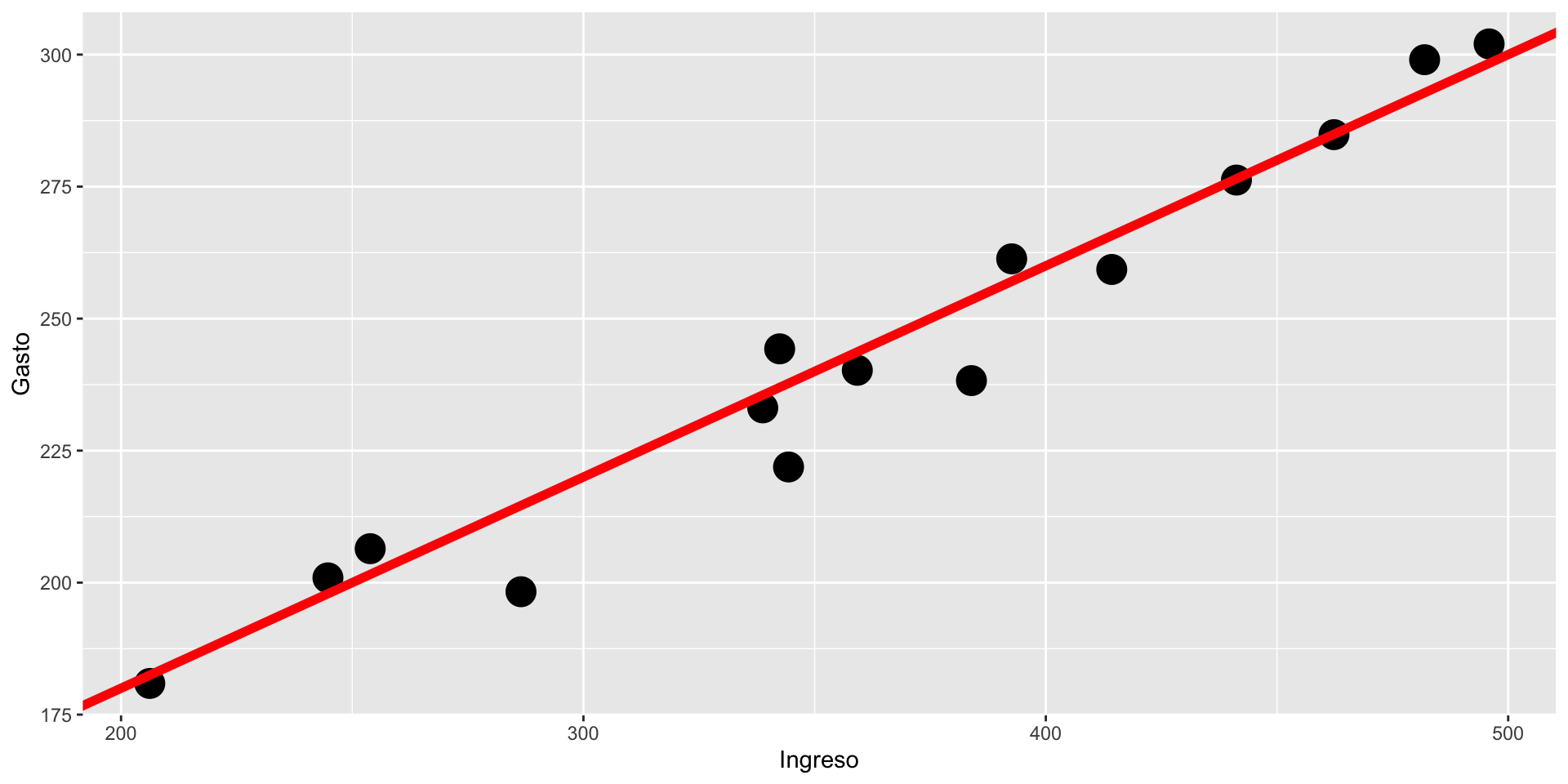
Objetivo: para un conjunto de datos \(y_1,\cdots,y_n\) y \(x_1,\cdots,x_n\), encontrar la recta que mejor ajusta a los puntos.
Estimación de un modelo de regresión simple
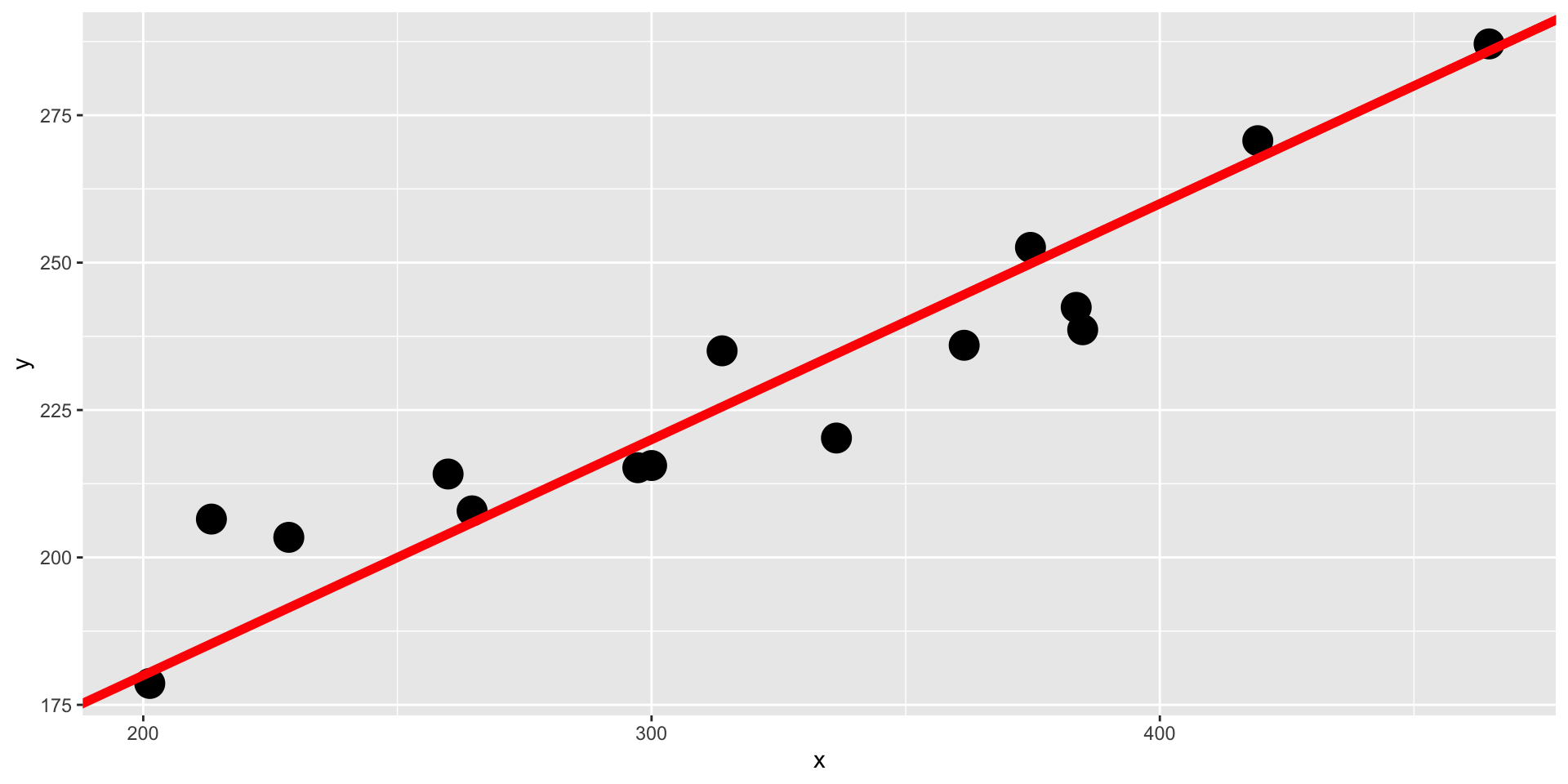
Objetivo: para un conjunto de datos \(y_1,\cdots,y_n\) y \(x_1,\cdots,x_n\), encontrar los valores \(\hat{\beta}_0\) y \(\hat{\beta}_1\) tales que la recta \[y_i=\hat{\beta}_0+\hat{\beta}_1x_i\] mejor ajusta a los puntos.
Solución: Minimizar \[Q=\sum_{i=1}^n[y_i-(\hat{\beta}_0+\hat{\beta}_1x_i)]^2\] Resolver \[\frac{\partial Q}{\partial\beta_0}=0\ \ \text{y}\ \ \frac{\partial Q}{\partial\beta_1}=0\]
Estimación de un modelo de regresión simple
Se tiene que \[ \begin{cases} n\hat{\beta}_0 + \hat{\beta}_1\sum x_i&=\sum y_i\\ \hat{\beta}_0\sum x_i + \hat{\beta}_1\sum x^2_i&=\sum x_iy_i\\ \end{cases}\]
Resolver las ecuaciones: \[\hat{\beta}_1=\frac{n\sum x_iy_i - \sum x_i\sum y_i}{n\sum x^2_i-(\sum x_i)^2}=\frac{S_{xy}}{S_{xx}}\] \[\hat{\beta}_0=\bar{y}-\hat{\beta}_1\bar{x}\] Las dos expresiones anteriores son los estimadores de mínimos cuadrados ordinarios (MCO en español, OLS en inglés)
Cálculo de estimaciones MCO
Datos de PC e ingreso per cápita
pais ingreso pc
1 Alemania 27610 48.47
2 Arabia Saudita 13230 13.67
3 Argentina 11410 8.20
4 Australia 28780 60.18
5 Bélgica 28920 31.81
6 Brasil 7510 7.48Cálculo de estimaciones MCO
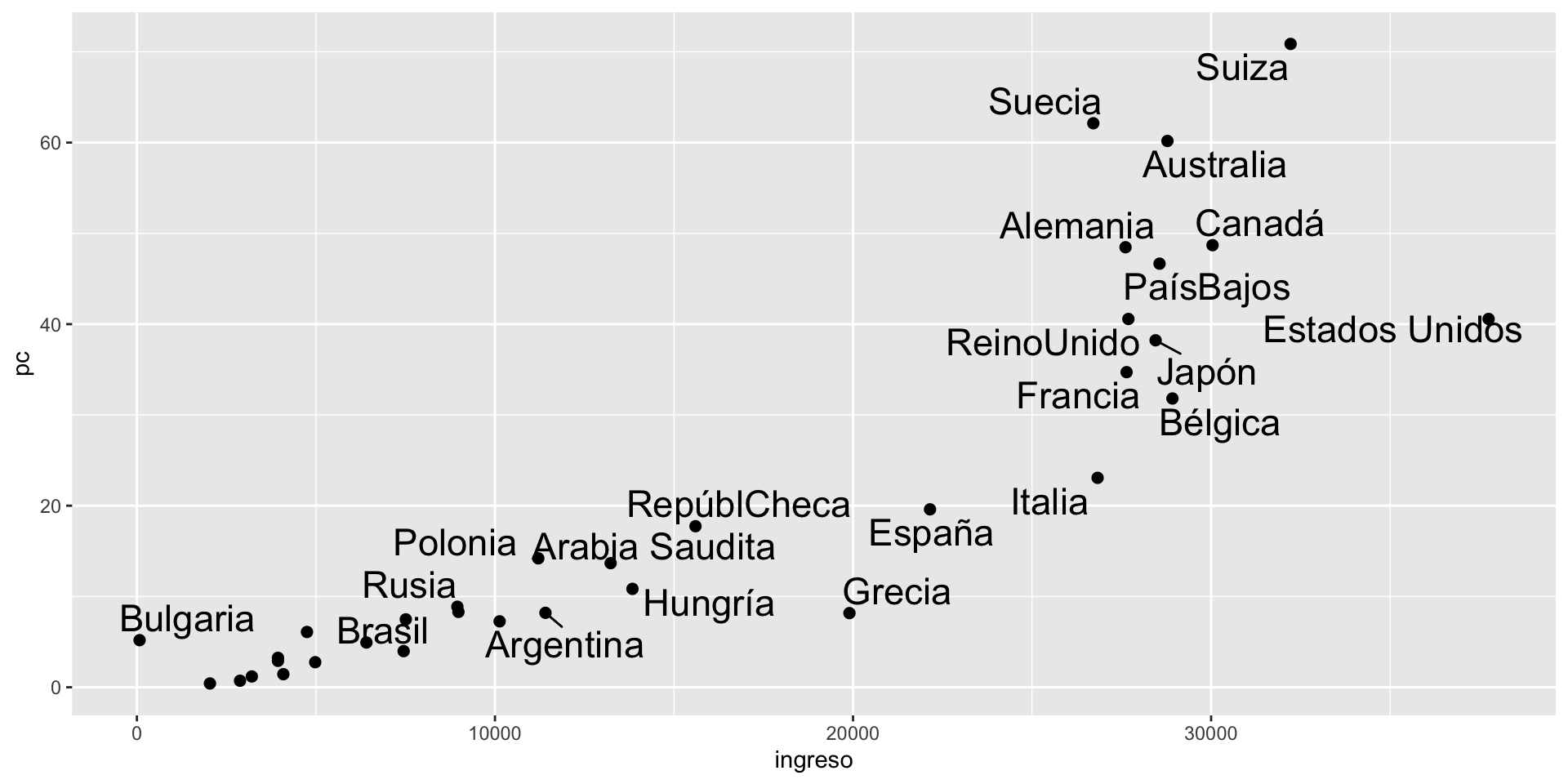
Cálculo de estimaciones MCO
El valor del intercepto estimado es
El valor de la pendiente estimada es
Cálculo de estimaciones MCO
Interpretación del intercepto
Interpretación 1: la esperanza de \(y\) cuando \(x\) vale 0 \[\beta_0=E(y_i|x_i=0)\]
Ejemplo: \(Y\): Gasto, \(X\): Ingreso, \(\beta_0\): gasto promedio incluso cuando no hay ingreso.
❗Dependiendo del contexto económico, \(\beta_0\) puede no tener esta interpretación, porque el contexto económico no permite que \(x\) sea 0, (ejemplo: salario en función de la edad)
Interpretación del intercepto
Interpretación 2: la parte de \(y\) que no depende de \(x\)
\[y_i=\underbrace{\beta_0}_{\text{no depende de x}}+\underbrace{\beta_1x_i}_{\text{depende de x}}\]
Ejemplo: \(Y\): precio de deptos, \(X\): área, \(\beta_0\): gasto fijo por apto (costo de tasación, gastos notariales, etc.)
Interpretación de la pendiente
\(\beta_1\): el incremento en \(y\) cuando \(x\) aumenta una unidad.
Cuando \(x\) aumenta en 1 unidad, \(y\) aumenta en \(\beta_1\) unidades.
\[\beta_1=\frac{\partial}{\partial x_i}E(y_i|x_i)\]
El signo de \(\beta_1\) coincide con el de \(\rho(x,y)\) y determina el tipo de relación lineal (proporcional o inversamente proporcial).
La magnitud de \(\beta_1\) representa la magnitud de efecto de \(x\) sobre \(y\).
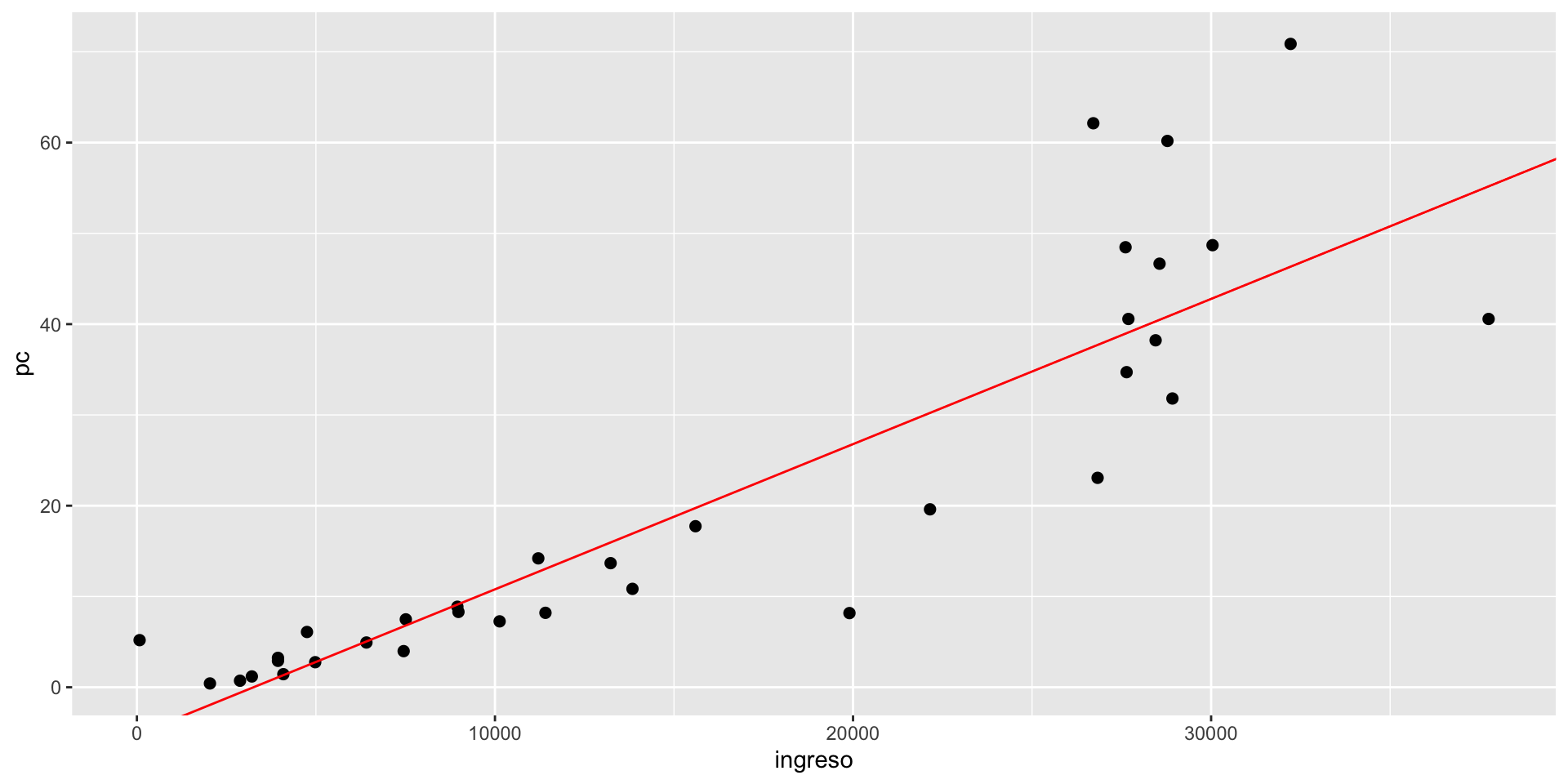
Interpretación de los coeficientes estimados
Nuestro ejemplo:
\[PC_i=-5.211 + 0.001637*Ingreso_i\]
¡El valor del intercepto no tiene interpretación!
Por cada dólar que se aumente en el ingreso anual promedio, el número de PC por cada 100 habitantes aumenta en 0.001637 computadores.
Interpretación de los coeficientes estimados
1. ¿Según el modelo, si el ingreso anual promedio de un país aumenta 2000 dólares, cómo será el cambio en el número de PC por cada 100 habitantes?
R: si el ingreso anual promedio de un país aumenta 2000 dólares, el número de PC por cada 100 habitantes aumentará en 3.274 computadores.
Interpretación de los coeficientes estimados
2. ¿Según el modelo, si el ingreso anual promedio de un país disminuye 1500 dólares, cómo será el cambio en el número de PC por cada 100 habitantes?
R: si el ingreso anual promedio de un país disminuye 1500 dólares, el número de PC por cada 100 habitantes disminuirá en 2.455 computadores.
Interpretación de los coeficientes estimados
3. Colombia en el 2003 cuenta con 4.93 computadores por cada 100 habitantes, si el gobierno quisiera aumentar la cifra a 6 computadores por 100 personas, según el modelo, en cuánto debe aumentar el ingreso anual promedio?
R: para que el número de computadores por cada 100 habitantes aumente de 4.93 a 6 computadores, el ingreso anual promedio debe aumentar en 654 dólares.
Interpretación de los coeficientes estimados
4. ¿Según el modelo, si el ingreso anual promedio de un país aumenta en un 30%, cómo es el cambio en el número de PC por cada 100 habitantes?
R: no se puede determinar, porque no se conoce el aumento absoluto en dólares.
Interpretación de los coeficientes estimados
5. ¿Según el modelo, si el ingreso anual promedio de un país disminuye en un 20%, cómo es el cambio en el número de PC por cada 100 habitantes?
R: no se puede determinar, porque no se conoce la disminución absoluta en dólares.
Resumen de interpretaciones de la pendiente
La interpretación de la pendiente de un modelo de regresión lineal está en términos de aumentos (o disminuciones) absolutos y no relativos
En un modelo de regresión lineal simple, si la variable \(X\) aumenta en \(m\) unidades, la variable \(Y\) aumenta en \(m\times\beta_1\) unidades.
Tarea 1 💻
Utilice los datos Datos_Venta_Propiedades.xlsx
Elige una de las comunas (con un número suficiente de departamentos) de la Región Metropolitana
Estimar el modelo de regresión para explicar el precio en términos del área.
Escribir la ecuación del modelo estimado.
Interpretar el intercepto y la pendiente.
¿En promedio, cuál es la diferencia de precio entre 2 deptos de esta comuna si una tiene 15 m2 más que la otra?
Tarea 2 💻
Objetivo: Predecir el precio de un auto usado de marca Jeep conociendo el kilométro.
Elabora gráfica de caja e histograma para la variable km.
¿Detectas datos pocos comunes (datos atípicos o outliers)?
Elabora gráfica de caja e histograma para la variable km.
¿Detectas datos pocos comunes (datos atípicos o outliers)?
Elimina los registros que consideras que puedan ser erróneos.
Tarea 2 💻
Elabora la gráfica de dispersión entre km y el precio e interpretar
Calcular el coeficiente de correlación entre km y el precio e interpretar
Estimar el modelo de regresión para explicar el precio en términos del km, escribe la ecuación.
Interpretar el intercepto y la pendiente.
¿En promedio, en cuánto se devalúa el auto por 10 mil kilométros adicionales?
¿En promedio, cuánto vale un auto Jeep de 50 mil kilométros?
Tarea 2 💻
Elige dos modelos de Jeep (por ejemplo, Cherokee y Patriot, o Wrangler y Compass).
Para cada modelo, repite los ejercicios del 5 al 11.
Compara los resultados para los dos modelos de Jeep.